这篇CVPR的文章我之前在做面试的project的时候略读过,但是对其中的细节把握的不是很到位,所以这次拿出来再重新精读一遍。
论文背景
对于SISR(单图像超分辨)问题,现在一般的解决方法分为两大种:基于模型的方法(model-based)和基于学习的方法(learning-based)
基于模型的方法(model-based)
经典的退化模型如下:
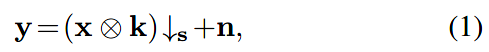
x是HR图像。k是模糊核。s代表s-折下采样(s-fold downsampler),即只保留每个s×s的patch中的左上角的一个像素。n通常是一个加性的高斯白噪声。
在基于模型的方法中,上面的退化模型得到了广泛的研究,该方法在MAP框架下求解数据项和先验项的组合。
优点:可解释性,可以灵活处理不同的放大系数、模糊核、噪声级别
缺点:一般采用双三次退化而不考虑模糊核和噪声水平。然而,双三次退化在数学上是复杂的,这反过来又阻碍了基于模型的方法的发展。
基于学习的方法(learning-based)
经典的基于CNN的方法,基本采用的是端到端(end to end)的训练模型,本质是基于大量数据学习一个双三次退化的LR到HR的非线性映射。
优点:模型容量大、并行计算速度快
缺点:缺乏灵活性,无法灵活处理不同的放大系数、模糊核、噪声级别。
深度展开网络(unfolding/unrolling network)
展开技术为“领域知识”与“数据(和经验)”的结合提供了一种有效的途径。所谓"展开",是指我们将求解一个给定连续模型的迭代优化看成是一个动态系统,进而通过若干可学习模块来离散化这一系统,得到数据驱动的演化过程的方法。
与单纯的学习方法相比,深度展开方法具有可解释性,能够将退化约束融合到学习模型中。
但是作者表示,现有的深度展开方法有以下一种或几种不足:
- 在不使用CNN的情况下,先验子问题的求解能力不够强大,无法获得良好的性能。
- 数据子问题没有采用闭合解(closed-form solution),可能会阻碍收敛。
- 整个推理是通过分段和微调的方式进行训练的,而不是完整的端到端方式。
主要贡献
- 第一次通过一个单一的端到端训练模型,尝试处理经典退化模型与不同的尺度因子、模糊内核和噪声水平;
- 为弥合基于模型方法和基于学习的方法之间的差距提供了途径;
- 本质上提出了一个退化约束(即,估计的HR图像应符合退化过程)和一个先验约束(即,估计的HR图像应该具有自然特征)上的解决方案;
- 在不同退化设置的LR图像上表现良好,显示了巨大的实际应用潜力。
方法详述
首先对于图像恢复模型,使用MAP最大后验概率,能量函数如下:
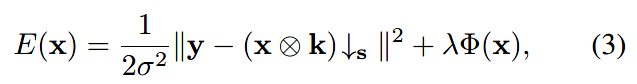
即数据项+正则项,\(\sigma\)是高斯噪声的标准差。
利用半二次分裂,分成两个可迭代的子问题:
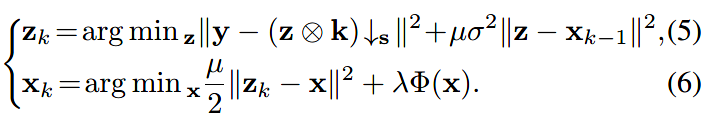
前者为数据子问题,后者为先验子问题(\(\Phi\)为先验项)。
对两个子问题分别求解:
数据子问题及其模型
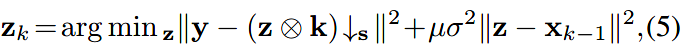
数据子问题的形式,利用FFT,有一个闭合解:
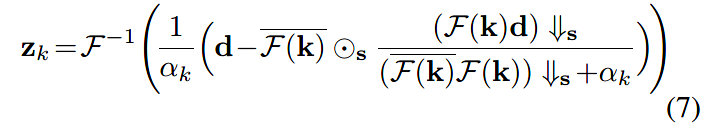
其中
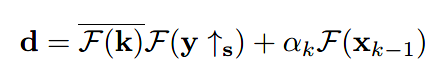
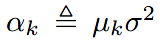
转换成网络模型为:
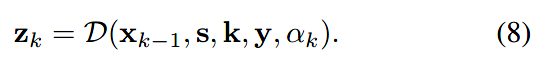
这里,\(\pmb{\rm x}_{k-1}\)是上一次迭代的输出;\(\rm\pmb s\)为缩放系数;\(\rm\pmb k\)为模糊核;\(\rm\pmb y\)为LR图像;\(\alpha_k\)为噪声水平\(\sigma\)和超参数\(\mu_k\)决定的。
值得注意的是,式(8)中不包含可训练参数,这使得数据项与先验项完全解耦,从而具有更好的可推广性。
先验子问题及其模型
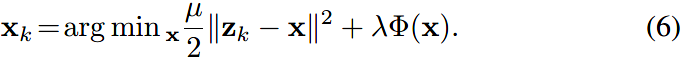
这里令: \[ \beta_k =\sqrt{\frac \lambda {\mu_k}} \] 上式就变成了: \[ {\rm\pmb x_k}=\arg \min_{\rm x} \frac 1 {2\beta_k^2}\|\rm\pmb {z_k - x}\|^2+\Phi(x) \] 从贝叶斯的角度来看,它实际上对应于某个噪声水平\(\beta_k\)(和之前的高斯噪声不是同一个)的去噪问题。
于是这个先验模型表示为:
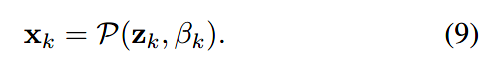
\(\rm\pmb z_k\)为上一个数据模型的输出;\(\beta_k\)是代表“去噪等级”的超参数。
这个先验网络的具体结构采用了U-net+ResNet的结构。按照按照U-Net的设置,ResUNet包括四个尺度,每个尺度在降级和升级操作之间都有一个跳跃连接(skip)。通道数分别是:64, 128, 256, 512。下采样采用跨步卷积,上采样使用转置卷积。
超参数生成器
对于上述两个模型,都存在有超参数,即数据子问题中的\(\alpha_k\)与\(\rm \pmb s\)以及先验子问题中的\(\beta_k\)。为了实现端到端的训练,作者提出了另一个超参数生成器模型(hyper-parameter generation)。
其中,数据子问题中的\(\alpha_k=\mu_k\sigma^2\),先验子问题中的\(\beta_k=\sqrt{\frac \lambda {\mu_k}}\)。而\(\sigma\)和\(\rm\pmb s\)是作为已知的输入,所以超参数生产器实际上要生成的超参数就是\(\mu_k\)和\(\lambda\),所以超参数生成器表示为:
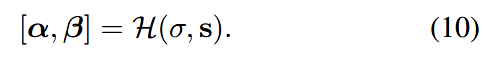
为了使性能更好,每次迭代都使用不同的\(\alpha\)与\(\beta\),所以超参数生成器的输出实际为:\(\pmb{\alpha}=[\alpha_1, \alpha_2,\alpha_3,...,\alpha_k]\),\(\pmb{\beta}=[\beta, \beta,\beta,...,\beta]\)。
其结构是三层全连接层,前两层的激活函数是ReLU,最后一层为Softplus。
网络总体结构
总体结构如图:
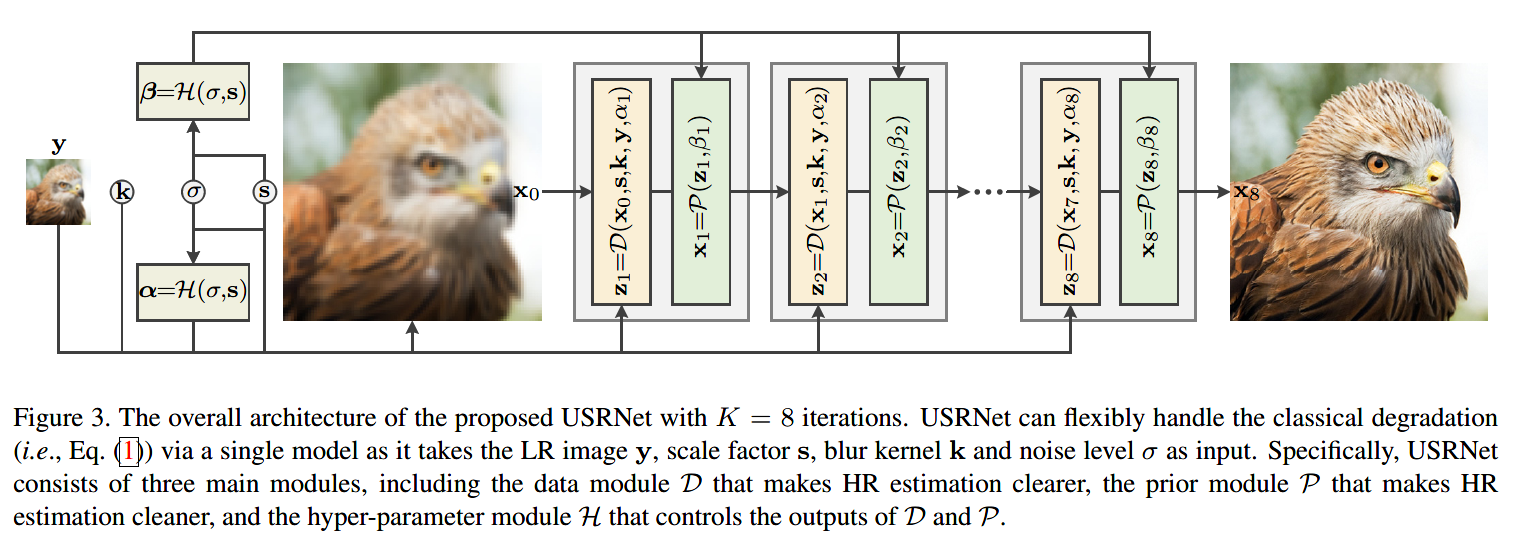
其中,D网络(数据子问题模型)不含可训练参数,图中多个P网络(先验子问题模型)的参数是共享的。
端到端的训练过程
训练数据集设计
使用DIV2K和Flickr2K的作为HR。LR图片由退化模型进行人工合成,缩放系数设置为1、2、3、4,模糊核采用大小为25×25的各向异性高斯核以及运动核,高斯噪声等级设置为[0, 25]。
损失函数
一开始先使用L1损失进行训练,得到模型之后,再使用:L1损失+VGG感知损失+相对对抗损失 (relativistic adversarial loss, 就是Relativistic GAN中的对抗损失),进行模型的调整,称为USRGAN。
实验结果
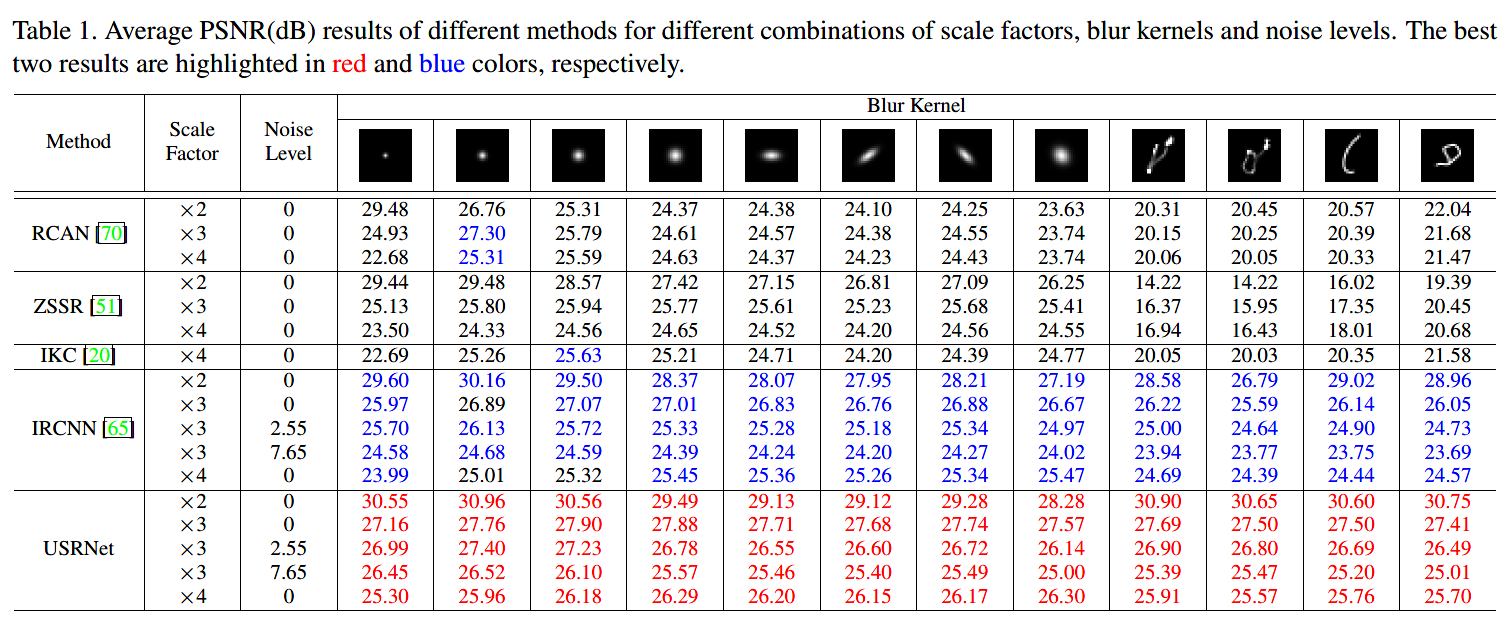
PSNR结果
可视化结果

对D和P网络的结果分析
观察不同迭代次数的结果:

作者发现,P也可以作为高频恢复的细节增强器。此外,P也没有减少模糊核引起的退化,验证了D和P之间的解耦。
对H网络的结果分析
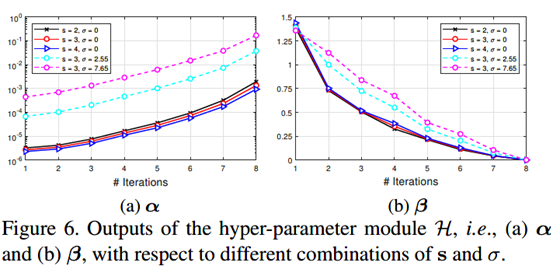
可以看出随着迭代次数的增加,beta呈递减趋势;但beta随着尺度因子和噪声水平的增加而增加。这说明,在迭代过程中,HR的先验会逐渐减少占比;以及,在复杂的退化过程中,需要一个更大的\(\beta\)来处理这一ill-posed问题。
总结与思考
- 这类深度展开的方法,通过MAP+半二次分裂,把model-based和learning-based的方法的优点结合在一起,感觉很惊艳。这相当于让“知识”和“数据”对最终的模型都有了贡献。
- 作者在文中还提到了一个与深度展开有点类似的工作,叫做deep plug-and-play方法,也可以把model-based和learning-based的方法结合起来,我准备把之后把这篇工作也仔细看一下