薅百度的羊毛
这几天做软件杯的项目的时候,为了实现文本中关键词关系的抽取,clone了github上的一个TensorFlow项目。该项目需要较高配置的GPU,本地跑不了,因此开始尝试寻找免费的算力资源。发现百度AI平台上面提供AI studio的算力平台,配置了Tesla V100-SXM2的GPU,算力超强。更重要的是,每天登录都可领12小时的算力卡。但是本平台只支持PaddlePaddle(飞桨)深度学习平台,于是开始搜索资料,尝试在其上面配置tensorflow-gpu。
主要参考的教程
这个知乎回答已经把主要的流程写出来了,但是我在照着做的时候,还是遇到了一些细节的问题,因此写这篇博客梳理一下。
预备步骤
在多次配置后发现,百度的机器比较玄学,每次启动的时候,机器配置都会发生改变:有时候是32G的显存,有时候是16G的显存;有时候是396.37版本的显卡驱动,有时候又是418.39的版本。这样的不确定性导致每次配置之前,都得注意其显卡驱动的版本(AI studio并不提供sudo权限,无法自行升级显卡驱动)。
后来发现了,早期的鸟儿有虫吃!早上打开环境,更高几率获得32G的显存及418.39的版本的驱动。
于是每次配置之前,使用以下命令查看NVIDIA驱动的版本:
1 | $ nvidia-smi |
然后会显示以下输出:(以我某次的输出为例)
1 | Tue Mar 3 15:20:05 2020 |
其中Driver Version: 396.37就是显卡驱动版本信息。
另外,当后续跑代码的时候,也可以利用此命令来监控GPU的状态,验证GPU是否在工作。
这里提供Nvidia驱动版本与CUDA版本的对应关系:
| CUDA Toolkit | Linux x86_64 Driver Version | Windows x86_64 Driver Version |
|---|---|---|
| CUDA 10.2.89 | >= 440.33 | >= 441.22 |
| CUDA 10.1 (10.1.105 general release, and updates) | >= 418.39 | >= 418.96 |
| CUDA 10.0.130 | >= 410.48 | >= 411.31 |
| CUDA 9.2 (9.2.148 Update 1) | >= 396.37 | >= 398.26 |
| CUDA 9.2 (9.2.88) | >= 396.26 | >= 397.44 |
| CUDA 9.1 (9.1.85) | >= 390.46 | >= 391.29 |
| CUDA 9.0 (9.0.76) | >= 384.81 | >= 385.54 |
| CUDA 8.0 (8.0.61 GA2) | >= 375.26 | >= 376.51 |
| CUDA 8.0 (8.0.44) | >= 367.48 | >= 369.30 |
| CUDA 7.5 (7.5.16) | >= 352.31 | >= 353.66 |
| CUDA 7.0 (7.0.28) | >= 346.46 | >= 347.62 |
同时,tensorflow-gpu的版本与CUDA和CUDA版本之间也有对应:
| Tensorflow-GPU | CUDA |
|---|---|
| 2.0 | 10.1 |
| 1.15 | 10.0 |
| 1.14 | 10.0 |
| 1.13 | 10.0 |
| 1.12 | 9.0 |
| 1.5 | 9.0 |
| 1.4 | 8.0 |
| 1.0 | 8.0 |
这里值得注意的是,TensorFlow-GPU对CUDA的版本及其严格,必须完全与上表对应,否则都无法正常运算。比如TensorFlow-gpu 1.12,必须对应CUDA9.0,CUDA9.2也不行,import的时候会报错。
另附:
TensorFlow各版本的下载地址(清华源):
https://pypi.tuna.tsinghua.edu.cn/simple/tensorflow-gpu/
CUDA各版本的下载地址:
https://developer.nvidia.com/cuda-toolkit-archive
CUDNN各版本的下载地址:
https://developer.nvidia.com/rdp/cudnn-archive
主要步骤
需要安装正确版本的CUDA、cuDNN。这里以安装CUDA10.0为例。(注意:必须符合驱动版本要求)
下载并安装CUDA
下载CUDA10.0的安装包:
1 | $ wget https://developer.nvidia.com/compute/cuda/10.0/Prod/local_installers/cuda_10.0.130_410.48_linux |
获得一个cuda_10.0.130_410.48_linux可执行文件。
执行以下命令安装cuda 10.0,实际就是在当前目录下,生成了一个cuda_10.0的库文件夹:
1 | $ sh cuda_10.0.130_410.48_linux --silent --toolkit --toolkitpath=$HOME/cuda_10.0 |
下载并导入cuDNN库文件
下载cuDNN v7.6.4, for CUDA 10.0:
1 | $ wget https://developer.download.nvidia.cn/compute/machine-learning/cudnn/secure/7.6.4.38/Production/10.0_20190923/cudnn-10.0-linux-x64-v7.6.4.38.tgz?RmkwolGzfXCe3BzgvLvAGvIyj5pIjHANLKL3MvnNYd0zxhgOfohxlIU9JjwUshKylDJdgSCbYTWtWYlDuBKE_omlbjg1GVZpRw_dt1VR095j1IcZcH_mkzcfViSViZgsvTD0PMOrD3sYj96AFFnV-dM_gwpoRzSnZAJMA_K010rhfdEvINFaYB9azWuJ42oUNzmsRgbtam8YUOkVKAbK5Agi3YVZY2ajGw |
解压cudnn-10.0.tgz:
1 | $ tar zxvf cudnn-10.9.tgz |
之后会生成一个名为cuda文件夹,执行以下命令,将cuDNN的库放进刚刚安装生成的cuda_10.0文件夹的对应目录:
1 | $ cp cuda/include/cudnn.h cuda_10.0/include/ |
配置环境变量
上述两步生成的cuda_10.0文件夹,会被Baidu Studio作为用户文件一直保存,因此以后每次登陆环境无需重新配置。
但从这一步开始(包括后续步骤),每次启动服务器的时候都需重新配置。因此,最后可以写成一个.sh脚本文件,脚本文件的内容我会总结在最后。
1 | $ chmod a+r cuda_10.0/include/cudnn.h |
安装tensorflow-gpu
根据CUDA版本(对应关系见上文的表)以及自身需求,选择合适版本的tensorflow-gpu下载 各版本下载地址
另外还要注意tensorflow-gpu与python版本的对应关系,观察下载的.whl文件名即可判断其适配的python版本:
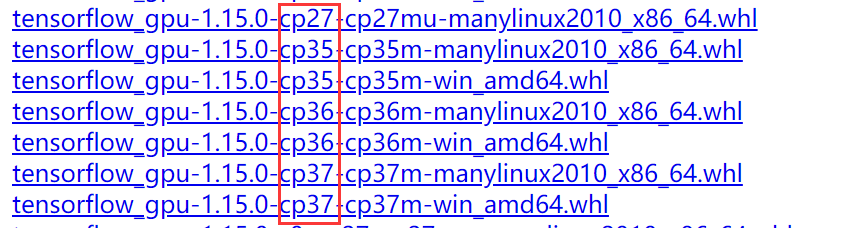
此处以tensorflow-gpu 1.15.0,python 3.7为例。
下载: 1
$ wget https://pypi.tuna.tsinghua.edu.cn/packages/bc/72/d06017379ad4760dc58781c765376ce4ba5dcf3c08d37032eeefbccf1c51/tensorflow_gpu-1.15.0-cp37-cp37m-manylinux2010_x86_64.whl#sha256=1344a3541e19e5b5cfde1c7b71fb02cb2f593262841a0e064df033619137f609
pip安装:
1 | $ pip install tensorflow_gpu-1.15.0-cp37-cp37m-manylinux2010_x86_64.whl |
大功告成!
最后利用下列python代码测试GPU是否在tensorflow下正常工作:
1 | import tensorflow as tf |
返回True则代表配置成功。
编写启动脚本
1 | $ vim start.sh |
键入以下内容并保存:
1 |
|
这里我用的是anoconda虚拟环境,所以多了一些conda配置。
以后每次启动环境后,只需键入以下命令,即可配置完成:
1 | $ source start.sh |